Цифровой Гербарий МГУОбсуждение / Ресурсы по ботанике / Форум
определитель растений онлайн
Справка
Просмотры: 97515Обсуждение
| Наталья Гамова | (продолжение)
У этого образца, как видите, можно посмотреть дополнительные данные.
Этикетка
|
| Наталья Гамова | (продолжение)
Если подвинуть полосу прокрутки тут, в геопривязке, вниз - будет видна расшифровка обозначения точности (она может быть разной в зависимости от точности описания местоположения в тексте этикетки и наличия\отсутствия координат)
|
| Анна Малыхина | Спасибо огромное, Наталья, за подробное освещение всех возможностей Гербария!!! Ваша команда - огромные молодцы!!! |
| Владислав Григоренко | Спасибо за инструктаж! "Ноев ковчег" rulez! |
| Наталья Гамова | Мы рады!
Спасибо за отклик)
И - ко всем пользователям ещё просьба.
Если у вас что-то НЕ работает - пишите, пожалуйста. И по возможности делайте скриншот страницы, если какие-то ошибки выдаёт и т.п.
Это важно.
Будем править (отправим вопросы программистам) |
| Наталья Гамова | 28.02. Америка индексирована по странам!
Эта работа целиком сделана нашими волонтерами. Накануне Нового года мы раздали задания: блоки по 500 образцов, у каждого из которых нужно было определить страну происхождения. Для 80% образцов страна была ясно указано на этикетке, а вот для остальных 20% нужно было копаться в Интернете, атласах и справочниках, ломать голову над почерком. В общем, понемногу задача была к концу февраля решена.
Оценить общее число участников этой большой работы почти невозможно. Помимо наших подписчиков, которые получили задание напрямую, помощь в этой работе оказали студенты Филиала МГУ в Севастополе под руководством Е. Беликиной.
Свои блоки сделали Елизавета Денисова, Илья Федюшко, Владимир Береснев, два блока - Нана Кондратьева. Почти 3 тыс. образцов привязала к странам практикант из Мос. пед. университета Дарья Туманова.
Уточненными метаданными снабжено 9,5 тыс. образцов из 12,5 тыс. Большинство образцов нашего американского гербария, как выяснилось, происходит из США, Канады, Гренландии, Кубы и Парагвая. Другие страны встречаются гораздо реже. Из некоторых государств (например, Белиза или Венесуэлы) выявлено всего по одному гербарному образцу.
Огромная благодарность за коллективный труд: это был интересный опыт организации процесса.
PS. В заначке у нас еще есть пара блоков американского гербария для желающих. |
| Наталья Гамова | 02.03. OCR гербария мохообразных: скоро на портале
Конверты отдела мохообразных Гербария Московского университета были отсканированы и помещены в Цифровой гербарий МГУ ( https://plant.depo.msu.ru/ ) "как есть", то есть без растений, спрятанных внутри. На гербарии мхов мы сейчас отлаживаем тотальный OCR всех наших сканов. Все образцы, в этикетках которых есть печатная информация (а таких - сотни тысяч), получат в базе данных особое поле, в котором будут сохранены результаты распознавания текста с изображений.
На этих двух картинках - оригинальная этикетка  и неотредактированный результат ее распознавания.
и неотредактированный результат ее распознавания.
 Текст, полученный при OCR, будет использоваться как для индексации изображений для целей поиска, так и в качестве исходника для внесения информации в полноценную базу данных. Это сделает работу наших операторов продуктивнее в разы.
Текст, полученный при OCR, будет использоваться как для индексации изображений для целей поиска, так и в качестве исходника для внесения информации в полноценную базу данных. Это сделает работу наших операторов продуктивнее в разы. |
| Наталья Гамова | 04.03
Статистика Цифрового гербария МГУ на конец февраля 2018 г.
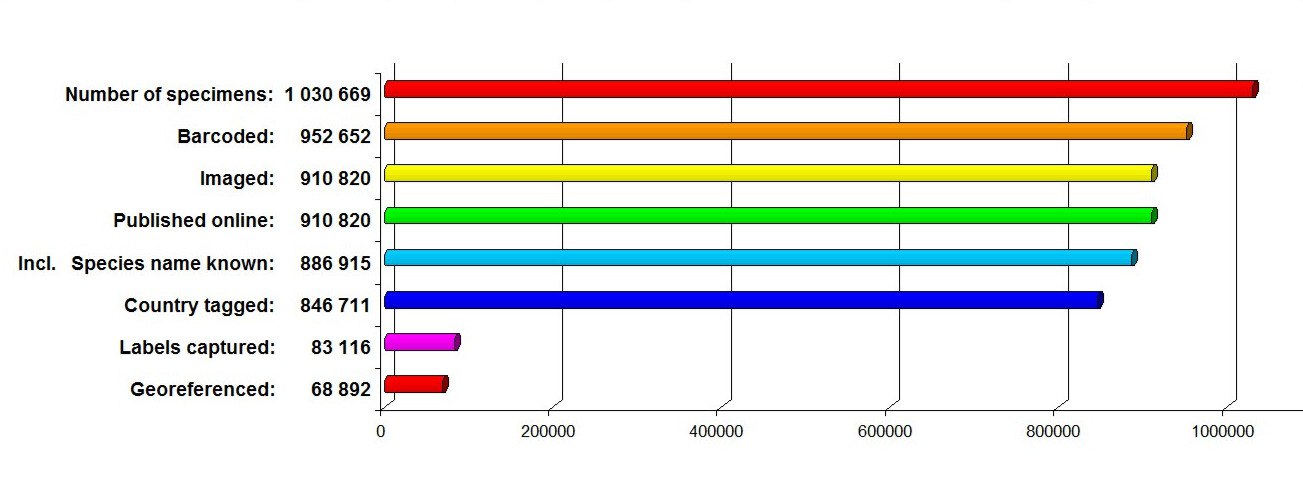 |
| Оксана Великова | Наталья, подскажите, пожалуйста, а как увидеть не только, сколько фото растений представлено в Беларуси, а и количество таксонов? https://plant.depo.msu.ru/open/public/search?queryString=E3a&searchBy=any&division=p&x=11&y=11 |
| Наталья Гамова | Оксана, количество таксонов вряд ли можно вывести..
(уточню, но вроде так и есть, потому что принятые в коллекции названия - обычно те, что в отечественной систематике приняты - они далеко не всегда совпадают с "внешней" базой данных, т.е. и числа будут разными, и подсчёты не идут).
И проще их просматривать в таблице выдачи результатов расширенного поиска https://plant.depo.msu.ru/module/itemsearchpublic |
| Анна Малыхина | Статистика впечатляет! |
| Юрий Постников | Наталья Гамова пишет:
14 января 2018 Наталья рассказала о "внутренней кухне" гербария MW. А именно, о процедуре. О том, КАК гербарий становится цифровым. Здорово, спасибо. Фактически, это приглашение к диалогу.) Давайте обсудим За кулисами Цифрового гербария МГУ  Еще раз, кратко, эта процедура, насколько я ее понял:
1) "программа-ридер автоматически присваивает файлу номер по штрихкоду" (= номер становится именем файла)
2) получаем файл в формате xls со столбиком, в котором содержатся имена (=номера) файлов
3) этап стандартизации номенклатуры (пункты 6 и 7 у Натальи). Здесь, насколько я понял, в файл со столбиком имен (номеров) файлов - вручную - заполняется название вида с этикетки, а также район;
4)потом, этот файл правится, исправляется; = при помощи "скрипта" (фунция ВПР, встроена в эксель) "сравнивается" с "эталонным" файлом-списком названий видов (= "стандартный перечень принятых в коллекции названий")
5) далее ручная правка "невставших" имен
6) далее программисты грузят сканы на портал, используя получившийся файл, как "ключ" (=перечень ключей)
7) Victoria!
Если все так, то вы в одном шаге от того, чтобы желающие гербарии, имеющие кучу сканов, попали к вам;
гербариям нужно приготовить этот, подобный, - предварительный! - ключ-файл;
а именно, файл, описанный выше в п2 и п3;
и передать его вам вместе со сканами;
п4, п5, и п6 - это уже ваша работа; большей частью - автоматизированная;
теоретически, можно попробовать; для опыта нужен один смельчак-гербарий,
и 10 его сканов;
Еще раз, кратко, эта процедура, насколько я ее понял:
1) "программа-ридер автоматически присваивает файлу номер по штрихкоду" (= номер становится именем файла)
2) получаем файл в формате xls со столбиком, в котором содержатся имена (=номера) файлов
3) этап стандартизации номенклатуры (пункты 6 и 7 у Натальи). Здесь, насколько я понял, в файл со столбиком имен (номеров) файлов - вручную - заполняется название вида с этикетки, а также район;
4)потом, этот файл правится, исправляется; = при помощи "скрипта" (фунция ВПР, встроена в эксель) "сравнивается" с "эталонным" файлом-списком названий видов (= "стандартный перечень принятых в коллекции названий")
5) далее ручная правка "невставших" имен
6) далее программисты грузят сканы на портал, используя получившийся файл, как "ключ" (=перечень ключей)
7) Victoria!
Если все так, то вы в одном шаге от того, чтобы желающие гербарии, имеющие кучу сканов, попали к вам;
гербариям нужно приготовить этот, подобный, - предварительный! - ключ-файл;
а именно, файл, описанный выше в п2 и п3;
и передать его вам вместе со сканами;
п4, п5, и п6 - это уже ваша работа; большей частью - автоматизированная;
теоретически, можно попробовать; для опыта нужен один смельчак-гербарий,
и 10 его сканов; |
| Оксана Великова | Наталья Гамова пишет: Понятно, Наталья, жаль! А на Плантариуме практически для любого места, любого уровня количество таксонов можно посмотреть - хоть итоговое значение по сайту, хоть количество для страны,..., или собственноручно загруженных. И это удобно и важно, и было ожидание аналогичного алгоритма.Оксана, количество таксонов вряд ли можно вывести.. |
| Наталья Гамова | В Плантариуме одна база, а там сразу две, поэтому подсчёты убраны.
Можно просто загрузить себе экселевскую табличку и смотреть в ней..
в этой табличке выгрузки результатов по всему району E3a нажать сперва "все строки" (в выпадающем окне тоже отметить галочкой "все строки") - в открывшейся полной таблице выделить всё (нажать на пустой квадратик в верхней левой ячейке таблицы) - и когда они выделятся все (будут покрашены жёлтым) - нажать справа вверху значок таблицы эксель - и по ссылке скачать таблицу. |
| Павел Евсеенков | Попытался получить описанным способом таблицу для региона Крым. На втором шаге выяснилось что максимальное количество строк 20000, а образцов из Крыма больше. Что делать ? |
| Наталья Гамова | Написала Алексею Петровичу, как ответит - скажу. |
| Наталья Гамова | 14.03.
Мы опубликовали на https://plant.depo.msu.ru/ OCR 55 467 образцов мхов
OCR - это оптическое распознавание символов ( https://ru.wikipedia.org/wiki/Оптическое_распознавание_символов ). Про FineReader слышали? Значит, имеете представление об OCR.
Несколько месяцев назад Яндекс, проиндексировав 786 тыс. сканов Гербария МГУ для сервиса Яндекс.Картинки, прогнал наш массив через эту процедуру. Все печатные символы, слова и предложения, которые программа распознала на этикетках, стали использоваться для индексации изображений. Мхи, этикетки которых были отсканированы без открывания конвертов, проиндексировались почти идеально. Это был огромный шаг вперед в деле бесконечного структурирования сканов Цифрового гербария МГУ. У нас появилась уверенность в том, что в будущем мы самостоятельно осуществим OCR и опубликуем результаты на портале.
В течение пяти суток на мощностях Центра обработки данных МГУ с помощью программного продукта Tesseract ( https://ru.wikipedia.org/wiki/Tesseract ) проходила обработка и распознавание этикеток 77 тыс. сканов образцов мхов. Результаты чистились с помощью наших собственных скриптов, которые находили и убирали строки нераспознанной абракадабры рукописного текста. Кроме того, мы выкинули из результатов все этикетки, содержавшие меньше 100 символов или меньше 5 значимых слов.
Результаты располагаются в закладке "OCR" в паспортах образцов, доступны по поиску через форму "Поиск по тексту этикеток", а в open-версии располагаются справа внизу. Примеры на скриншотах.
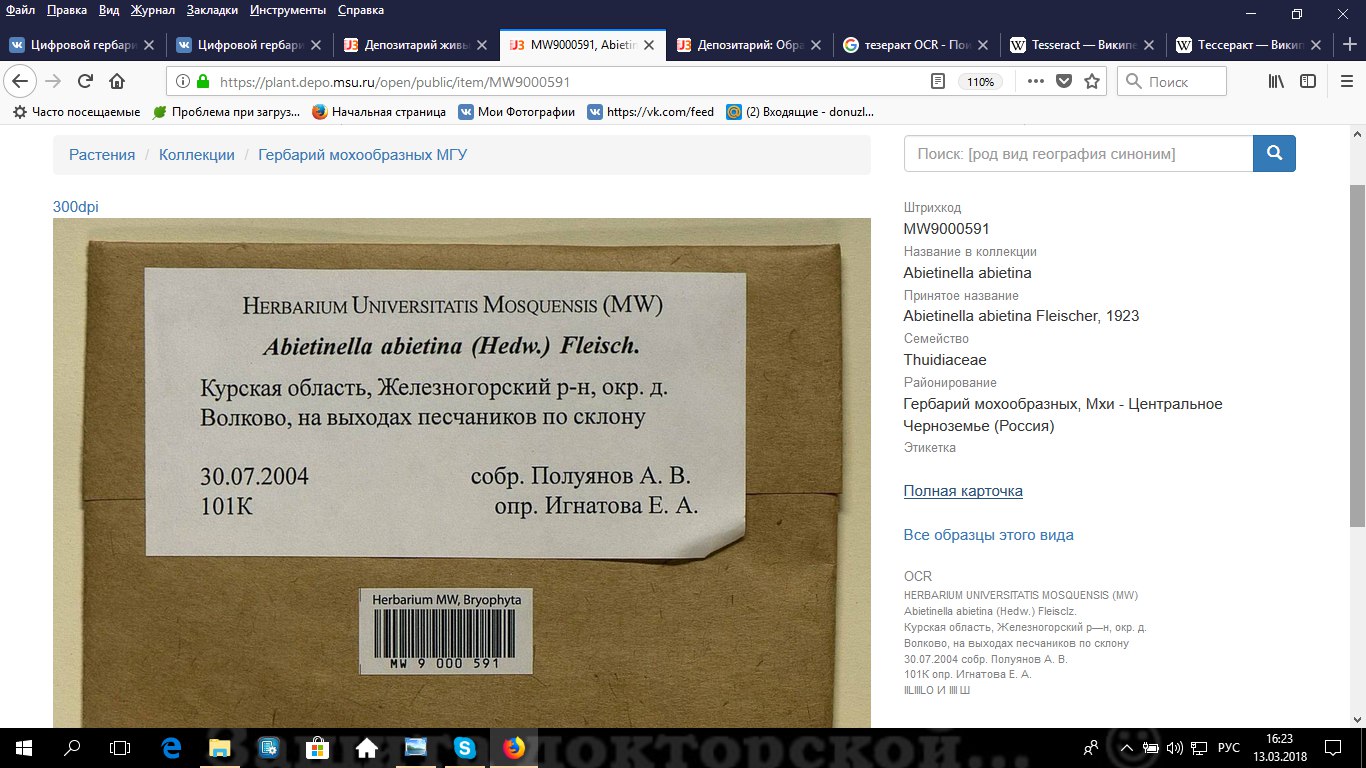 (OCR справа внизу мелким серым шрифтом)
(OCR справа внизу мелким серым шрифтом)
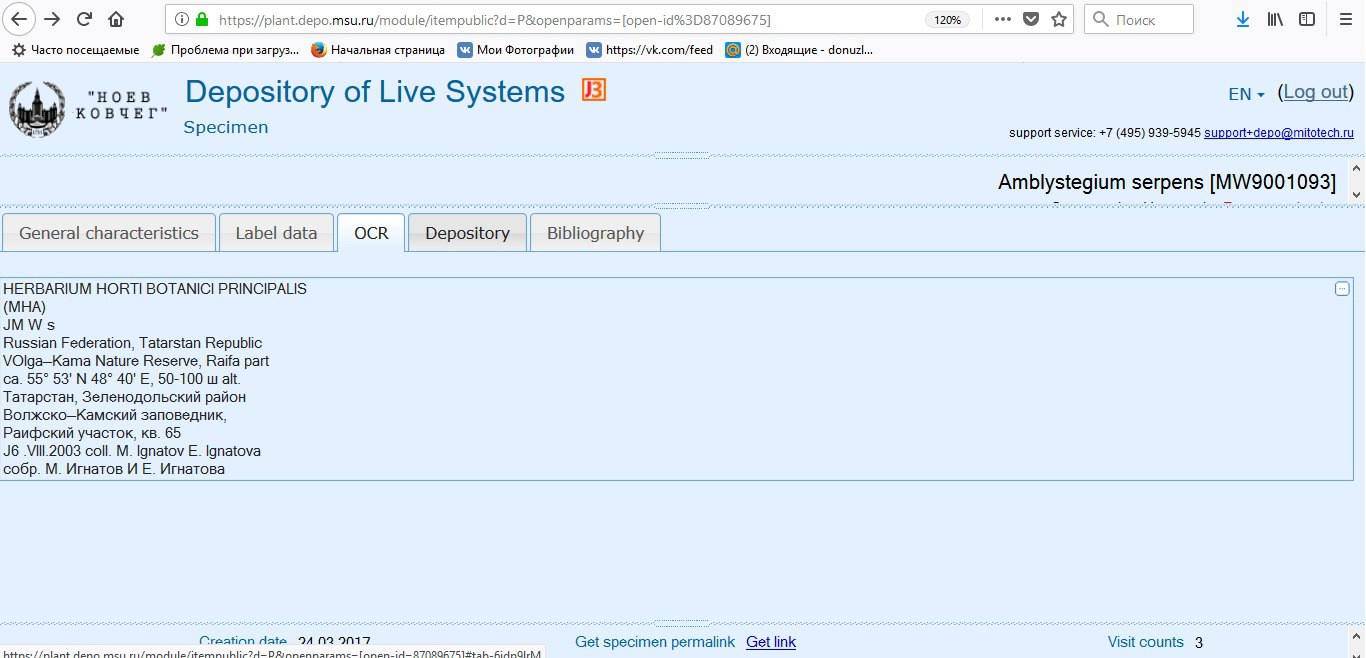 (паспорт образца. Результаты OCR в отдельной закладке)
(паспорт образца. Результаты OCR в отдельной закладке)
 (так выглядит скан конверта мхов)
(так выглядит скан конверта мхов)
 (Здесь в поле OCR можно внести фамилию коллектора, например)
(Здесь в поле OCR можно внести фамилию коллектора, например)
 (Из 77 тыс. образцов мхов в 17 тыс. этикетках машина распознала фамилию Игнатов. Что, впрочем, неудивительно - Елена Анатольевна и Михаил Станиславович - основные коллекторы. Вторым по числу сборов идёт Владимир Эрнстович Федосов).
На этой неделе мы приступаем к сложному, но крайне необходимому OCR образцов сосудистых растений (825 тыс. сканов).
(Из 77 тыс. образцов мхов в 17 тыс. этикетках машина распознала фамилию Игнатов. Что, впрочем, неудивительно - Елена Анатольевна и Михаил Станиславович - основные коллекторы. Вторым по числу сборов идёт Владимир Эрнстович Федосов).
На этой неделе мы приступаем к сложному, но крайне необходимому OCR образцов сосудистых растений (825 тыс. сканов). |
| Наталья Гамова | 16.03
Модуль таксономии гибридов
Гибриды, имеющие бинарные названия, в Цифровом гербарии МГУ ( https://plant.depo.msu.ru/ ) рассматриваются наряду с биологическими видами. С такими названиями (например, Salix × onusta Besser или Geum × intermedium Ehrh.) у нас не возникало особых проблем, поскольку их стыковка с номенклатурой международных баз идет по родовому названию и имеющемуся видовому (точнее, нотовидовому) эпитету.
Другое дело - растения, которые определены с помощью гибридной формулы. Таких довольно много среди Salix, Dactylorhiza, Viola и ряда других родов. Мы разработали и внедрили модуль, который распознает в гибридной формуле родительские виды и "цепляет" к ним стандартный ID (и номенклатуру) с единого таксономического каркаса Цифрового гербария МГУ.
Так, например, образцы, имеющие название в коллекции "Crepis nigrescens × tectorum" автоматически приобретают стандартизированную гибридную формулу "Crepis nigrescens Pohle × Crepis tectorum L." (в этом случае, названия в коллекции и в международных базах совпадают).
Есть и более заковыристые варианты. Например, образцы Polygonum aviculare × calcatum автоматически тэгируются как "Polygonum aviculare L. × Polygonum arenastrum subsp. calcatum (Lindm.) R. Wisskirchen". На скриншотах даны некоторые примеры работы модуля.
В целом, мы нечасто храним растения, определенные как гибриды, в шкафах в отдельных гибридных обложках. Это связано с тем, что разные исследователи трактуют уклоняющиеся образцы то как свидетельство гибридизации, то как результат проявления изменчивости видов. Особенно часто такие разночтения встречаются в родах Salix и Carex. В связи с этим, гибриды стоит искать, прежде всего, среди родительских видов (например, у Pilosella).
примеры на скриншотах:


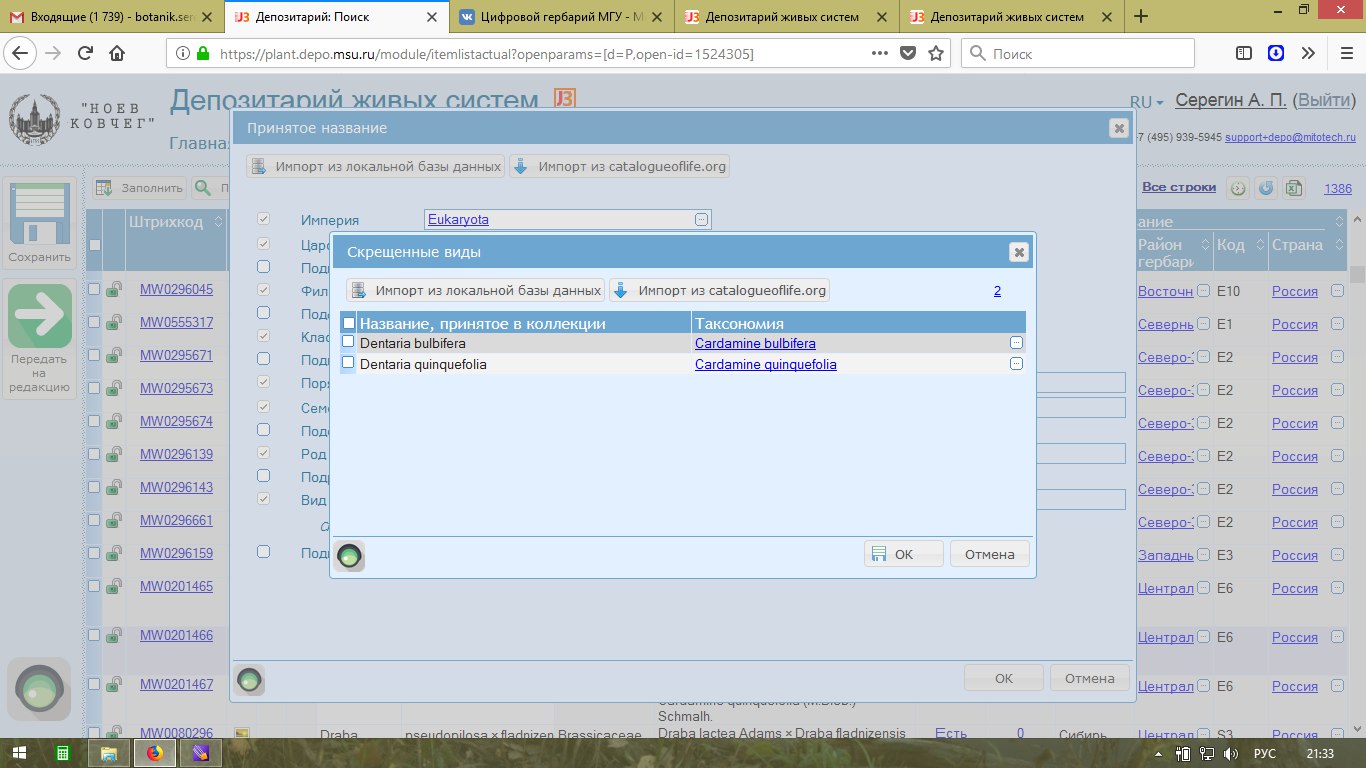
 |
| Наталья Гамова | 18.03.
Большая обзорная статья о трех годах проекта "Ноев Ковчег" (Национальный банк-депозитарий живых систем МГУ)
Каким-то фантастическим образом направление "Растения" оказалось в начале обзора. Кто не любит читать - полистайте картинки.
https://lenta.ru/articles/2018/03/05/noah/ |
| Наталья Гамова | 19.03.
OCR как инструмент поиска ошибок индексации
Как мы сообщали недавно, этикетки мхов Цифрового гербария МГУ были массово загружены в Центр обработки данных МГУ для оптического распознавания текста. Здесь - о примере практического использования полученных данных.
Все сканы Цифрового гербария МГУ ( https://plant.depo.msu.ru/ ) уже во время сканирования индексируются по двум параметрам - таксономия и география. И там, и там возможны ошибки, возникающие по нескольким причинам.
Например, географическая индексация образца идет по районам гербария (на картинке карта районирования гербария мхов). Случайно образец мха, собранный, например, на Чукотке (район 21), мог оказаться приклеенным на одну подложку с образцами с юга Дальнего Востока (район 20). Позднее, уже во время сканирования оператор мог случайно пометить образцы из района 15 как образцы из района 16. Совершенно естественно, что на 78 тыс. образцов гербария мохообразных таких ошибочек накопилось несколько сотен.
Читать глазами (хотя бы бегло) этикетки каждого образца чудовищно долго, да и взгляд оператора при этом быстро притупляется. Мы воспользовались тем, что 55 тыс. образцов мхов имеют печатные этикетки и были распознаны во время OCR. С помощью простых запросов, на которые ушло не больше часа, мы отловили большинство ошибок географической индексации.
Итак, в поле OCR мы вносили через запятую все возможные варианты написания регионов данного района и прочих ключевых слов, характерных только для этого района. Например, для района 21 этот запрос в поле OCR был примерно таким: "Чукотка, Камчатка, Командор, Врангеля, Магадан" + то же самое на английском. Параметр поиска был при этом "Искать не в районе 21". Система за доли секунды выдавала все такие образцы (от 5 до 50 "потеряшек" для каждого района), которые мы бегло проверяли глазами, а затем сохраняли исправленную географию в систему.
 (коды районов для гербария мхов)
(коды районов для гербария мхов) |
| Лена Глазунова | А направление "Животные", получается, весьма пунктирно пока представлено? Меня тут неожиданно заинтересовали хирономиды. Вернее, не меня, но очень помогли бы какие-нибудь базы микрофотографий... |
| Наталья Гамова | Оу. Про них много не скажу - сама смотрела сейчас..
если в направлении "животные" открыть "коллекции" - там, в общем, перечислен состав
в насекомых 623 образца сейчас значатся  |
| Лена Глазунова | Похоже, там двукрылых пока вообще нет  |
| Наталья Гамова | 17.03.18.
AMUR-100
Вчера на GBIF мы опубликовали большую новую базу данных. Коллектив авторов-сотрудников Гербария МГУ в составе С.В. Дудов, К.В. Дудова, Н.С. Гамова при участии нескольких помощников по гранту РФФИ 16-35-00505 ( https://istina.msu.ru/projects/17174586/ ) создал точнейшие карты распространения ста модельных видов в бассейне Амура. Страница датасета тут: https://www.gbif.org/dataset/0c7bd9e3-ded7-4de4-99ec-d5145361ff48
Всего в базе данных числится 12,371 привязанная к карте находка, каждая из которых основана на гербарных образцах из семи гербариев России. Этот кропотливый труд занял у коллектива почти два года. Из Гербария МГУ было учтено 1694 гербарных образцов, сведения о которых также пополнят Цифровой гербарий МГУ ( https://plant.depo.msu.ru/ ).
Представленная карта составлена на основании следующих российских коллекций: LE, MW, MHA, VLA, VBGI, NSK, и TK. По сути, это карта географической изученности флоры российской части бассейна Амура и прилегающих территорий.
Это еще один шаг на пути к созданию "Атласа флоры России". На сегодняшний день Московский университет опубликовал в GBIF сведения о 1,070,722 находках растений со всего земного шара, в т.ч. 227 тыс. находок с координатами.
( https://www.gbif.org/dataset/902c8fe7-8f38-45b0-854e-c324fed36303 )
 |
| Наталья Гамова | 23.03.18.
Дальний Восток, Гренландия, Канада, Красноярский край, тропики, Ростовская область: 4,5 тыс. новых геопривязок и 2,5 тыс. новых этикеток
В начале этой неделе мы активно заливали в Цифровой гербарий МГУ ( https://plant.depo.msu.ru/ ) новые текстовые и пространственные данные. Мы загрузили восемь (!) массивов данных. Результат налицо: число этикеток выросло с 83116 до 85583, число геопривязок - с 69040 до 73534.
Обо всем по порядку.
1. База данных "Флора бассейна Амура" ( https://www.gbif.org/dataset/0c7bd9e3-ded7-4de4-99ec-d5145361ff48 ) примерно на 15% состоит из записей, основанных на образцах Гербария МГУ. Текст этикеток 1690 образцов и такое же количество ручных геопривязок, залитые в Цифровой гербарий МГУ, стали первым значимым массивом из районов S4 (Прибайкалье и Забайкалье) и S6 (юг Дальнего Востока). Поскольку введены как этикетки, так и геопривязки, то теперь почти все сборы из бассейна Амура смогут получать автоматические привязки ИСТРОЙ. Операторы С.В. Дудов, К.В. Дудова, Н.С. Гамова и др.
2. Координаты 1386 образцов из Гренландии и Канады взяты с этикеток без ввода полных txt-данных. Почти на всех образцах они указаны с точностью до 1 минуты (примерно 1 км). Это стало возможным благодаря тому, что наши волонтеры раскидали зимой гербарий Америки по странам. Вынуть из этого массива образцы с координатами оказалось делом пары дней. Автор - Анастасия Борцова.
3. Мхи Владимирской области (сборы Ю.С. Кокошниковой) загружены благодаря OCR-обработке массива. После OCR мы смогли найти все сборы этого автора, использованные при подготовке "Флоры Владимирской области" и привязать их к готовой авторской таблице этикеток. Большинство образцов имеют координаты. Всего загружено 129 этикеток - это дублеты многочисленных сборов, хранящихся в Гербарии Нижегородского университета.
4. Экспорт образцов из базы данных TROPICOS возможен! Опять же благодаря OCR мы установили все образцы мхов, переданные нам в качестве дублетов из Миссурийского ботанического сада. Их оказалось 179 штук. Дальше по паре коллектор/коллекторский номер все этикетки в нужном формате были вынуты из TROPICOS ( http://tropicos.org/SpecimenSearch.aspx ). Большинство имеют координаты. Благодаря этой загрузке многочисленными точками мы накрыли многие страны Латинской Америки и Африки, Австралии и Океании. Для разнообразия.
5. Загружены полнотекстовые расшифровки 199 этикеток Урала: Пермский край, Башкирия, Оренбургская область. Автор Дарья Шарова.
6. Важным дополнением стали 618 образцов с парой коллектор+дата из района S3 (Красноярский край) - из них 598 штук имеют ручную геопривязку. Благодаря этой заливке кое-что из нашей базы дополнительно накрылось ИСТРОЙ. Автор массива - известный знаток флоры Таймыра и наш неутомимый волонтёр Игорь Николаевич Поспелов ( https://istina.msu.ru/profile/taimyr/ ). Теперь почти каждый образец района S3 при вводе ключевых метаданных будет получать автоматическую привязку.
7. И.Н. Поспелов скинул нам также фрагмент базы данных "Флора Таймыра", охватывающий 289 его образцов с Таймыра, которые были смонтированы и отсканированы в 2017 г. Все образцы также с геопривязками.
8. Наконец, наш волонтёр Анатолий Георгиевич Кузьмин прислал очередную порцию массовых геопривязок для растений Ростовской области в числе 1452 штук! Благодаря его усилиям, эта территория обладает одним из наиболее полных массивов геоинформации, основанных на сборах из Гербария МГУ: примерно треть образцов с Нижнего Дона уже получили метки на карте.
Это была прорывная неделя: мы никогда еще не заливали восемь массивов данных со всего мира за четыре дня. Огромное спасибо всем участникам процесса!
Пары картинок (было-стало)
1.  и
и 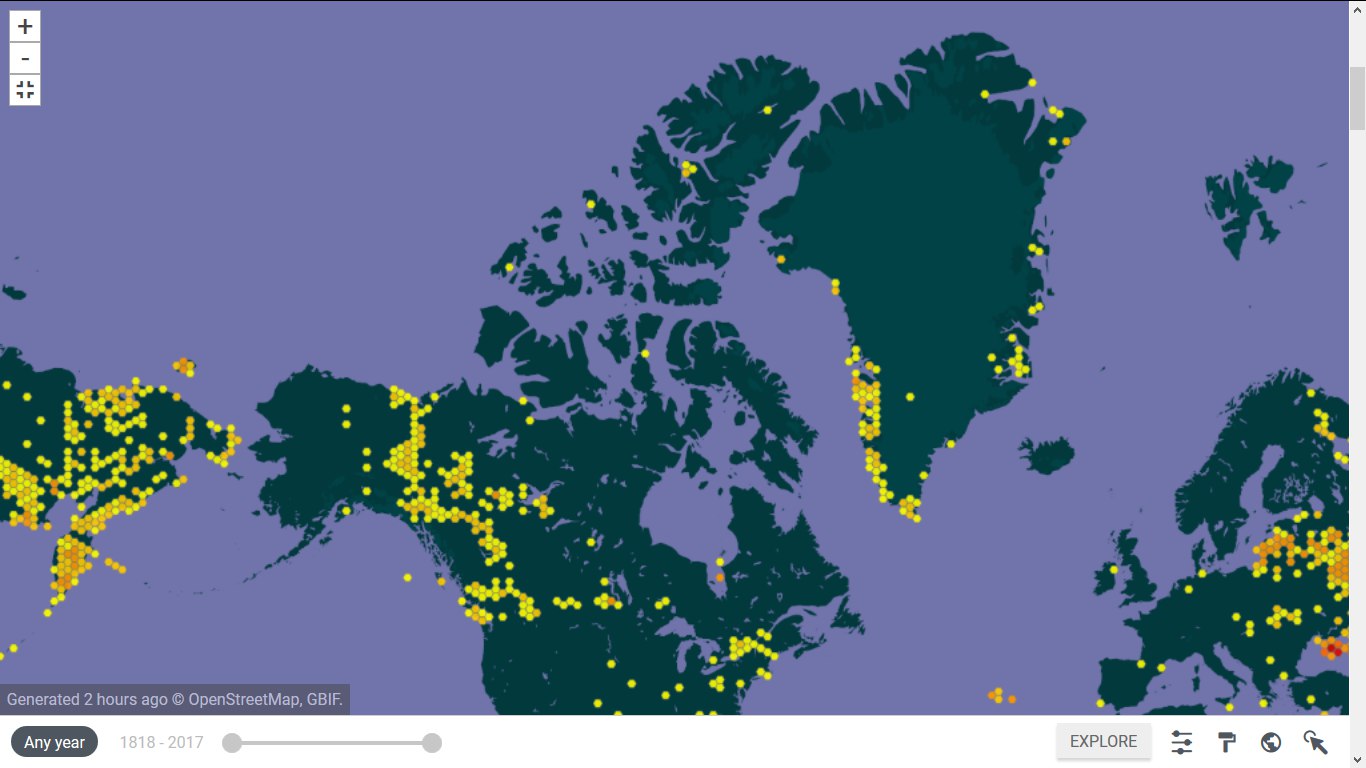 2.
2.  и
и  3.
3. 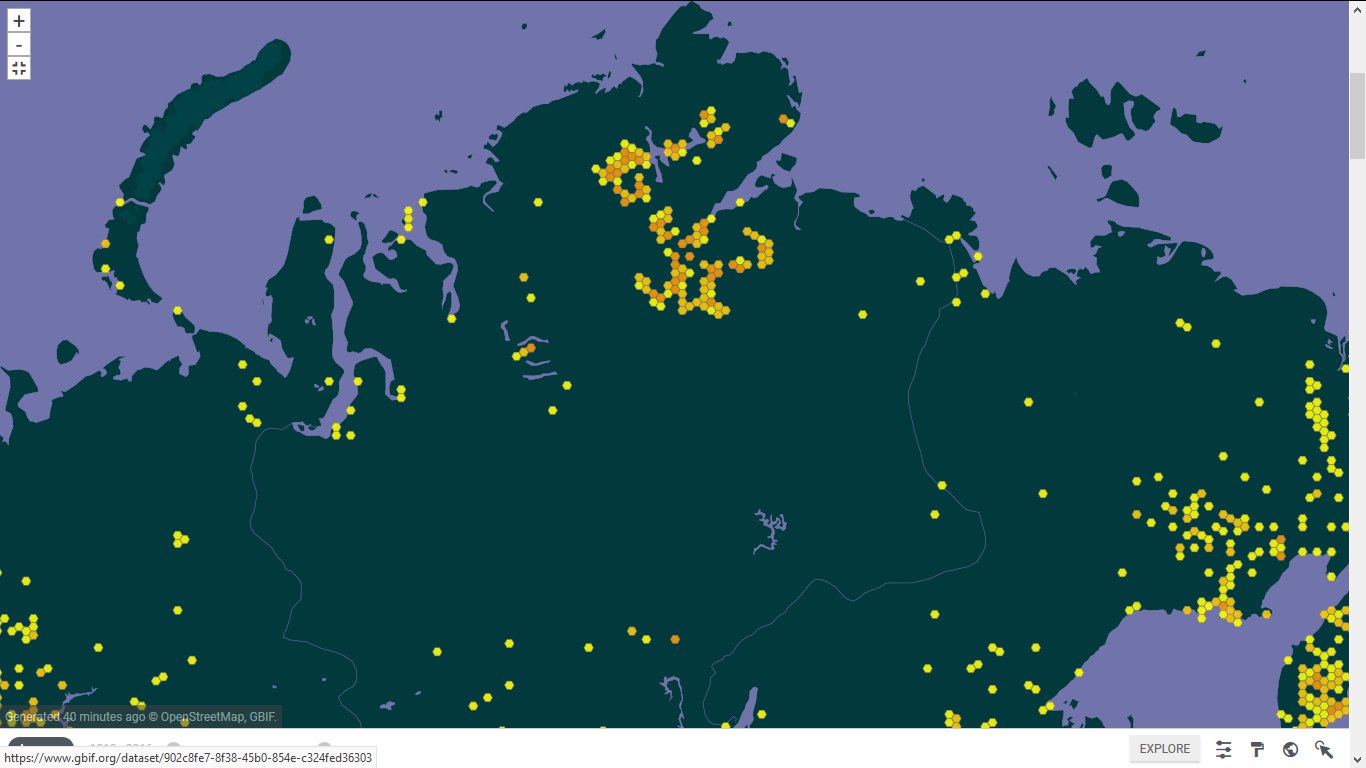 и
и  4.
4.  и
и 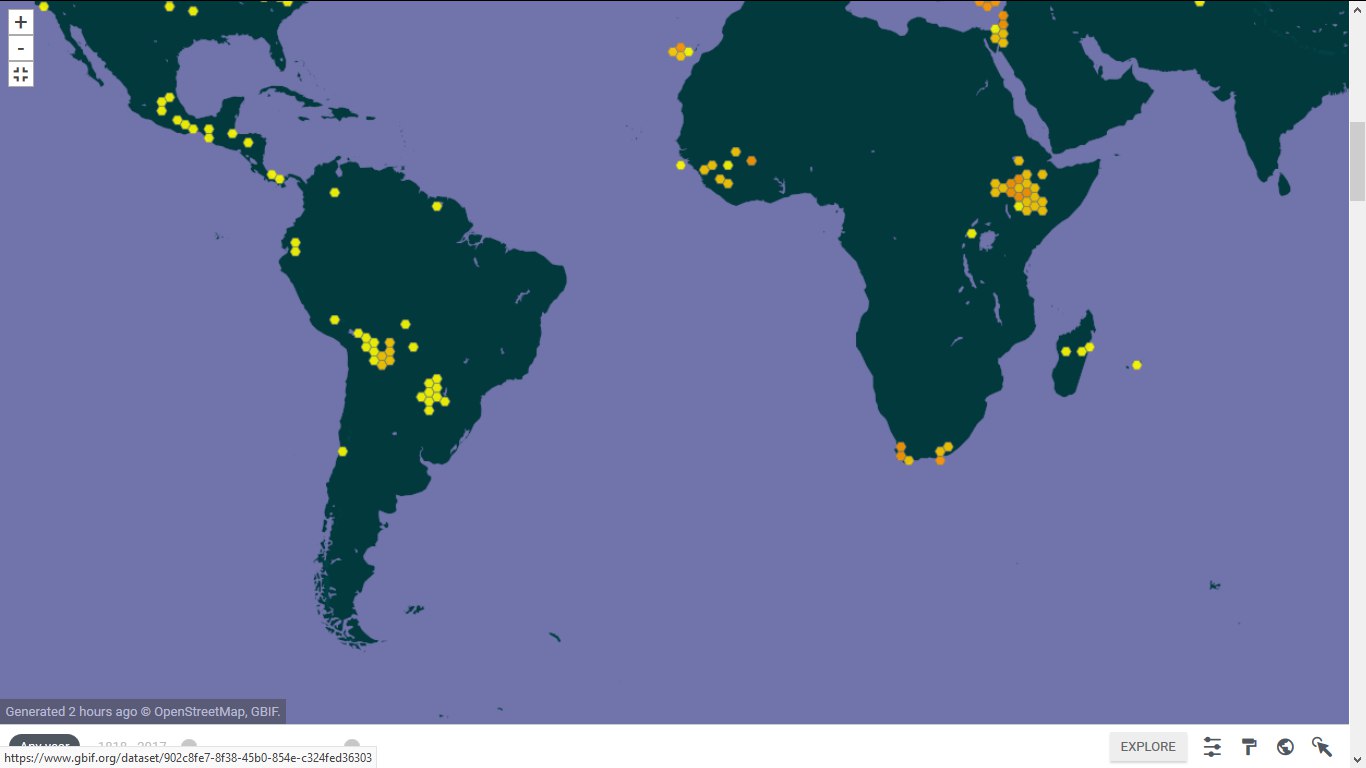 5.
5.  и
и  |
Растения и лишайники
Местообитания
Участник
Поиск
|
|
Обратная связь | Наверх |